By John Timmer
Computer algorithms have gotten much better at recognizing patterns, like specific animals or people’s faces, allowing software to automatically categorize large image collections. But we’ve come to rely on some things that computers can’t do well. Algorithms can’t match their image recognition to semantic meaning, so today you can ensure a human’s present by asking them to pick out images of street signs. And algorithms don’t do especially well at recognizing when familiar images are distorted or buried in noise, either, which has kept us relying on text-based CAPTCHAs, the distorted text used to verify a human is interacting with Web services.
Or we had relied on them ’til now, at least. In today’s issue of Science, a Bay Area startup called Vicarious AI describes an algorithm they created that is able to take minimal training and easily handle CAPTCHAs. It also managed general text recognition. Vicarious’ secret? They modeled the structure of their AI on information we’ve gained from studying how the mammalian visual cortex processes images.
Thinking visually
In the visual cortex, different groups of neurons recognize features like edges and surfaces (and others identify motions, which aren’t really relevant here). But rather than viewing a scene or object as a collection of these parts, the neurons start communicating among each other, figuring out by proximity which features are part of a single object. As objects are built up and recognized, the scene is built hierarchically based on objects instead of individual features.
The result of this object-based classification is that a similar collection of features can be recognized even if they’re in a different orientation or are partly obscured, provided that the features that are visible have the same relative orientations. That’s why we can still recognize individual letters if they’re upside down, backwards, and buried in a noisy background. Or, to use Vicarious’ example, why we can still tell that a chair made of ice is a chair.
To try to mimic the brain’s approach, the team created what they’re calling a Recursive Cortical Network, or RCN. A key step is the identification of contours, features that define edges of an object as well as internal structures. Another set of agents pull out surface features, such as the smoothness of a surface defined by these contours. Collections of these recognized properties get grouped into pools based on physical proximity. These pools then establish connections with other pools and pass messages to influence the other’s feature choices, creating groups of connected features.
Groups of related features get built up hierarchically through a similar process. At the top of these trees are collections of connected features that could be objects (the researchers refer to them as “object hypotheses”). To parse an entire scene with a collection of objects, the RCN undergoes rounds of message passing. The RCN creates a score for each hypothesis and revisits the highest ranked scores to evaluate them in light of other hypotheses in the same scene, ensuring that they all occupy a contiguous 2D space. Once an object hypothesis has been through a few rounds of this selection, it can typically recognize its object despite moderate changes in size and orientation.
High efficiency
The remarkable thing about the training is its efficiency. When the authors decided to tackle reCAPTCHAs, they simply compared some examples to the set of fonts available on their computer. Settling on the Georgia font as a reasonable approximation, they showed RCN five examples each of partial rotations for all the upper and lower case letters. At a character level, this was enough to provide over 94 percent letter recognition accuracy. That added up to solving the reCAPTCHA two-thirds of the time. Human accuracy stands at 87 percent, and the system is considered useless from a security standpoint if software can manage it with a one percent accuracy.
And it’s not just reCAPTCHA. This system managed the BotDetect system with similar accuracy and Yahoo and PayPal systems with 57 percent accuracy. The only differences involved are the fonts used and some hand-tweaking of a few parameters that adjust for the deformations and background noise in the different systems. By contrast, other neural networks have needed on the order of 50,000 solved CAPTCHAs for training compared to RCN’s 260 images of individual characters. Those neural networks will typically have to be retrained if the security service changes the length of its string or alters the distortion it uses.
To adapt RCN to work with text in real-world images, the team provided it with information about the co-appearance of letters and frequency of words use, as well as the ability to analyze geometry. It ended up beating the top-performing model by about 1.9 percent. Again, not a huge margin, but this system managed with far less training—the leading contender had been trained on 7.9 million images compared to RCN’s 1,406. Not surprisingly, RCN’s internal data representation was quite a bit smaller than its competitor’s.
This efficiency is a bit of a problem, as it lowers the hardware bar that must be cleared in order to overcome a major security feature of a variety of websites.
More generally, this could be a big step for AI. As with the Go-playing software, this isn’t a generalized AI. While it’s great for identifying characters, it doesn’t know what they mean, it can’t translate them into other languages, and it won’t take any actions based on its identifications. But RCN suggests that AI doesn’t need to be completely abstracted from actual intelligence—the insights we gain from studying real brains can be used to make our software more effective. For a while, AI has been advancing by throwing more powerful hardware, deeper pipelines, and bigger data sets at problems. Vicarious has shown that returning to AI’s original inspiration might not be a bad idea.
Science, 2017. DOI: 10.1126/science.aag2612 (About DOIs).
ARS SCIENCE VIDEO>
A celebration of Cassini
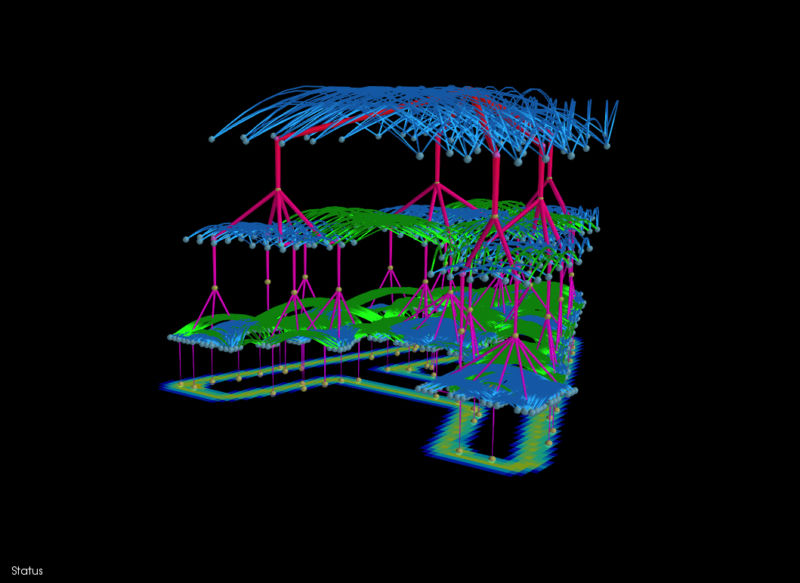
A representation of how physically close feature recognition units are built hierarchically to create an object hypothesis. Vicarious AI
Computer algorithms have gotten much better at recognizing patterns, like specific animals or people’s faces, allowing software to automatically categorize large image collections. But we’ve come to rely on some things that computers can’t do well. Algorithms can’t match their image recognition to semantic meaning, so today you can ensure a human’s present by asking them to pick out images of street signs. And algorithms don’t do especially well at recognizing when familiar images are distorted or buried in noise, either, which has kept us relying on text-based CAPTCHAs, the distorted text used to verify a human is interacting with Web services.
Or we had relied on them ’til now, at least. In today’s issue of Science, a Bay Area startup called Vicarious AI describes an algorithm they created that is able to take minimal training and easily handle CAPTCHAs. It also managed general text recognition. Vicarious’ secret? They modeled the structure of their AI on information we’ve gained from studying how the mammalian visual cortex processes images.
Thinking visually
In the visual cortex, different groups of neurons recognize features like edges and surfaces (and others identify motions, which aren’t really relevant here). But rather than viewing a scene or object as a collection of these parts, the neurons start communicating among each other, figuring out by proximity which features are part of a single object. As objects are built up and recognized, the scene is built hierarchically based on objects instead of individual features.
The result of this object-based classification is that a similar collection of features can be recognized even if they’re in a different orientation or are partly obscured, provided that the features that are visible have the same relative orientations. That’s why we can still recognize individual letters if they’re upside down, backwards, and buried in a noisy background. Or, to use Vicarious’ example, why we can still tell that a chair made of ice is a chair.
To try to mimic the brain’s approach, the team created what they’re calling a Recursive Cortical Network, or RCN. A key step is the identification of contours, features that define edges of an object as well as internal structures. Another set of agents pull out surface features, such as the smoothness of a surface defined by these contours. Collections of these recognized properties get grouped into pools based on physical proximity. These pools then establish connections with other pools and pass messages to influence the other’s feature choices, creating groups of connected features.
Groups of related features get built up hierarchically through a similar process. At the top of these trees are collections of connected features that could be objects (the researchers refer to them as “object hypotheses”). To parse an entire scene with a collection of objects, the RCN undergoes rounds of message passing. The RCN creates a score for each hypothesis and revisits the highest ranked scores to evaluate them in light of other hypotheses in the same scene, ensuring that they all occupy a contiguous 2D space. Once an object hypothesis has been through a few rounds of this selection, it can typically recognize its object despite moderate changes in size and orientation.
High efficiency
The remarkable thing about the training is its efficiency. When the authors decided to tackle reCAPTCHAs, they simply compared some examples to the set of fonts available on their computer. Settling on the Georgia font as a reasonable approximation, they showed RCN five examples each of partial rotations for all the upper and lower case letters. At a character level, this was enough to provide over 94 percent letter recognition accuracy. That added up to solving the reCAPTCHA two-thirds of the time. Human accuracy stands at 87 percent, and the system is considered useless from a security standpoint if software can manage it with a one percent accuracy.
And it’s not just reCAPTCHA. This system managed the BotDetect system with similar accuracy and Yahoo and PayPal systems with 57 percent accuracy. The only differences involved are the fonts used and some hand-tweaking of a few parameters that adjust for the deformations and background noise in the different systems. By contrast, other neural networks have needed on the order of 50,000 solved CAPTCHAs for training compared to RCN’s 260 images of individual characters. Those neural networks will typically have to be retrained if the security service changes the length of its string or alters the distortion it uses.
To adapt RCN to work with text in real-world images, the team provided it with information about the co-appearance of letters and frequency of words use, as well as the ability to analyze geometry. It ended up beating the top-performing model by about 1.9 percent. Again, not a huge margin, but this system managed with far less training—the leading contender had been trained on 7.9 million images compared to RCN’s 1,406. Not surprisingly, RCN’s internal data representation was quite a bit smaller than its competitor’s.
This efficiency is a bit of a problem, as it lowers the hardware bar that must be cleared in order to overcome a major security feature of a variety of websites.
More generally, this could be a big step for AI. As with the Go-playing software, this isn’t a generalized AI. While it’s great for identifying characters, it doesn’t know what they mean, it can’t translate them into other languages, and it won’t take any actions based on its identifications. But RCN suggests that AI doesn’t need to be completely abstracted from actual intelligence—the insights we gain from studying real brains can be used to make our software more effective. For a while, AI has been advancing by throwing more powerful hardware, deeper pipelines, and bigger data sets at problems. Vicarious has shown that returning to AI’s original inspiration might not be a bad idea.

{kind=link}